
#
Model Maker Role
Last update: May 20, 2024
#
#
Requirements
#
Before proceeding, ensure you meet these requirements.
#
#
#
Things to Avoid
#
This will disqualify your post
-
-
#
It lacks the correct files.
- The .ZIP file must contain both the correct
.INDEX&.PTHfile. Learn about them here.
#
#
Model is low quality.
A bad model:
- Sounds scratchy/screechy.
- Has a muffled sound.
- Sounds inaccurate to the source.
- Is incapable of hitting certain notes.
- Has slurred speech.
- Is unable of pronouncing words correctly in its intended language.
- Has artifacting.
#
#
An outdated extraction method was used.
#
#
The audio demo contains instrumental.
Don't include ANY music in the audio demo, even if it's not copyrighted. This is due to:
- Concerns over copyright.
- In many cases, the music can "hide" the flaws of the voice model, making it harder to judge its quality.
#
The audio demo is altered.
Don't add reverb, equalize, or alter the demo in any way, as it won't be a faithful representation of the model. It must be the raw, unmodified output from the inference.
Trimming silences at the beginning/end of the audio demo is allowed.
#
#
#
Steps
-
-
#
Step 1: Zip the model.
Gather the .PTH & .INDEX file and zip them into a
.ZIPfile.It must be a .ZIP file, not .7ZIP or .RAR.
#
#
Step 2: Upload it.
The ZIP must be stored in a Hugging Face public repository of
openraillicense.Learn how here.
#
#
Step 3: Prepare the submission.
Once your model is ready, head over to the #get-model-maker channel.
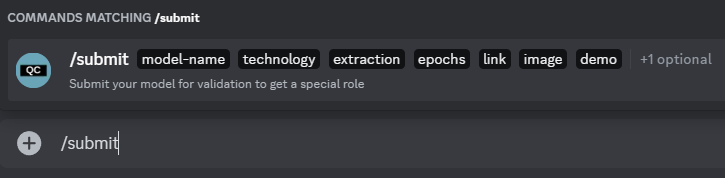
Type the
/submitcommand of QCBot and click the command.
#
Now fill up the information about your model:
- model-name
- Its name.
- technology
- The technology used for its training.
- extraction
- The extraction method you used.
- epochs
- Total epochs amount.
- link
- Its download link from Hugging Face.
- image
- An image of what it represents (person/character).
- demo
- An audio sample of it talking/singing.
- note
- Optional. Add more context about the model if you want.
You can attach more samples when you repost the model to #voice-models.
#
#
Step 4: Send submission.
Once you are done filling the information, send the message.
If everything went fine, your submission will be added to the queue & the bot will send a confirmation message, containing your submission ID.
With this ID, you can:- Check your submission's number in queue with the command
/queuefollowed by the ID. (e.g/queue 251). - Cancel your submission with the command
/cancelfollowed by the ID.
- Check your submission's number in queue with the command
Now, wait for a QC (quality checker) to verify your model. You'll be notified once it has been reviewed.
If your model gets approved, the bot will notify you with a message like this:

You can then repost the model (& future models) to the
#voice-modelsforum.