
#
Inference Settings
Last update: Feb 25, 2024
#
#
Introduction
When doing inference in RVC, you'll come across to quite a few options that you can tweak, that influence the conversion process.
Configuring them accordingly can improve the output quality by a lot, as well as reduce artifacting, so we highly recommend learning them.
There are some of them that are either obsolete or not important. So if a setting is not explained here, you can ignore it.
#
#
Explanation
#
#
Transpose

#
#
Also known as Pitch, it adjusts the tone of voice.
Negative values lower the tone (e.g
-2).Positive ones raise it (e.g
5).You can use decimals if necessary (e.g
-4.3).
You'll usually have to modify this for the pitch to sound perfect. Modify it until it matches the tone of the model.
#
#
Search Feature Ratio

#
Also known as Index Rate, it determines the level of influence of model's .INDEX file:
Higher values will apply more of the .INDEX's characteristics.
Lowering it can reduce artifacting.
Remember, if the dataset had other sounds like background noise, there will be noise in the .INDEX too.
#
#
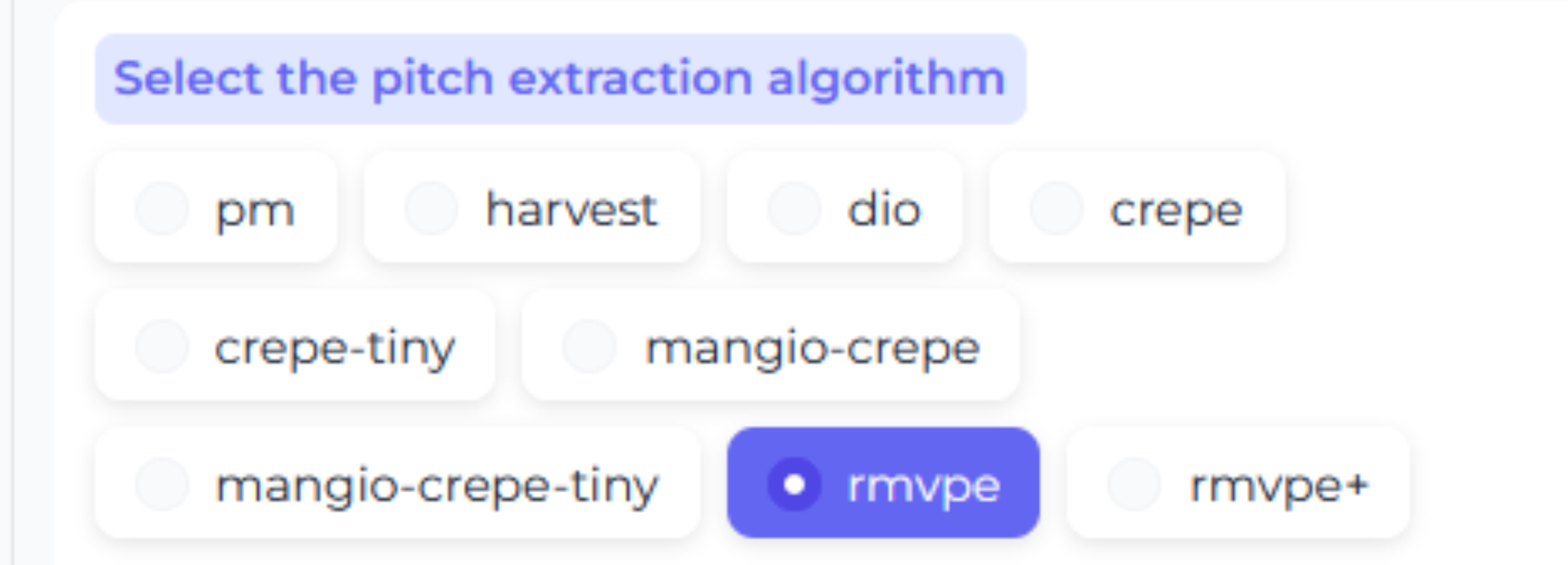
Pitch Extraction Algorithm
#
Also known as f0, they're the algorithms for converting the vocals.
Each one works in its own way, and has its pros & cons.
As the majority of them are obsolete, we'll focus on the 3 best ones: RMVPE, Crepe, & Mangio-Crepe.
RMVPE # - Fast
- Decent quality
- Usually sounds a little harsh
- Should be your go-to algorithm, due to its convenience
Some forks include RMVPE_GPU & RMVPE+. Same algorithm, but with a modification:
- RMVPE GPU:
- Training only. Uses more GPU power, making you train faster.
- RMVPE+:
-
Inference only. Allows you to set the maximum/minimum frequency, to reduce small distortions. Recommended for advanced users.
Crepe # - Slower
- Has higher quality
- More prone to noise & artifacting. Switch to RMVPE if you can't fix it
- Only use it with high quality datasets/samples
- Recommended for more realistic results
Mangio-Crepe # - It's crepe, but you can adjust its hop_length
- It determines the time it takes the voice to hit a note
- The lower the value, the more detailed results you'll get, but will take longer to process
- Useful when the audio/model performs drastic note shifts
# Lowering it too much might lead to voice cracks.
They also work the same for training models.
#
#
Protect Voiceless Consonants

#
Also known as Protection, they suppress breath sounds:
Decrease the value to remove more breath sounds, as they cause some artifacting.
A value of
0.5disables this feature.
Be careful, lowering it too much will make it voice sound "inhumane" & suppress part of the words.
#
#
Volume Envelope

#
Also known as Remix Mix Rate, controls the loudness of the output:
The closer to
0, the more the output will match the loudness of the input audio.The closer to
1, the more it will match the loudness of the dataset the model was trained on.
Basically, leave it at 0 if you want the audio to try to keep its original volume.
#
#
Split Audio
#
Gives a faster inference & more consistent output volume:
In RVC sometimes there's an error where the volume of the output lowers in some parts.
To prevent this, Split Audio divides the audio & infers them one by one. Then unites them at the end.
Doing it this way is faster too.